Optimizing Transferred Data For Performance And Scalability

Table of Contents
Data Compression Techniques for Efficient Transfer
Efficient data transfer often begins with effective compression. By reducing the size of the data before transmission, we significantly decrease transfer times and bandwidth consumption. Two main categories exist: lossless and lossy compression.
Lossless Compression
Lossless compression algorithms, such as gzip, deflate, and zstd, reduce file size without discarding any data. This is crucial for scenarios where data integrity is paramount.
- gzip: A widely used algorithm, offering a good balance between compression ratio and speed. It's commonly used for web servers to compress HTML, CSS, and JavaScript files.
- deflate: Another popular algorithm often used in conjunction with other protocols like ZIP. It offers comparable performance to gzip.
- zstd: A newer, faster algorithm offering higher compression ratios than gzip and deflate, particularly beneficial for large datasets.
However, lossless compression methods might not be suitable for every use case. They have limitations in compression ratios for certain data types and involve some CPU overhead during both compression and decompression. Use cases where lossless compression is crucial include database backups, critical system logs, and any scenario requiring perfect data fidelity. For more information, refer to the official documentation for each algorithm: , , .
Lossy Compression
Lossy compression techniques, unlike lossless methods, discard some data to achieve higher compression ratios. This is acceptable when some data loss is tolerable in exchange for smaller file sizes and faster transfer times.
- JPEG: A widely used lossy compression format for images, offering a good balance between image quality and file size.
- MP3: A popular lossy audio compression format, reducing audio file sizes without significant perceived loss in quality for many users.
- WebP: A modern image format developed by Google, supporting both lossy and lossless compression, and often offering superior compression compared to JPEG.
The trade-off between file size and data fidelity is the key consideration when choosing a lossy compression method. Tools like ImageMagick and ffmpeg offer powerful command-line options for various lossy compression tasks.
Data Deduplication and its Impact on Transfer Speed
Data deduplication significantly reduces data transfer times by eliminating redundant data before transfer. This is especially effective when dealing with large datasets containing many duplicate files or data blocks.
Identifying and Removing Duplicate Data
Data deduplication relies on identifying and removing duplicate data blocks. Common methods include:
- Hashing: Generating unique hash values for data blocks to quickly identify duplicates. Algorithms like SHA-256 are often used.
- Checksums: Calculating checksums to verify data integrity and identify duplicate blocks. CRC32 is a commonly used checksum algorithm.
Deduplication not only speeds up data transfer but also reduces storage space requirements, resulting in cost savings and improved storage efficiency.
Implementing Deduplication Strategies
Implementing deduplication can involve various approaches, including:
- Pre-transfer deduplication: Identifying and removing duplicates before initiating the data transfer process.
- Post-transfer deduplication: Deduplicating data after the transfer is complete.
- Inline deduplication: Deduplicating data during the transfer process itself.
Challenges in implementing deduplication include the computational overhead of identifying duplicates and the need for robust data management to track unique data blocks. Cloud-based deduplication services often provide easier implementation and management of these processes.
Optimizing Data Transfer Protocols and Networks
Choosing the right protocol and optimizing the network infrastructure are critical for efficient data transfer.
Choosing the Right Protocol
Different protocols offer varying levels of performance, security, and reliability.
- HTTP/2: A significantly improved version of HTTP, offering enhanced performance through features like multiplexing and header compression. Ideal for web applications.
- HTTPS: The secure version of HTTP, providing data encryption and authentication. Essential for any application handling sensitive data.
- FTP: A widely used protocol for file transfer, offering relatively simple implementation. However, it lacks built-in security features.
- SFTP: The secure version of FTP, providing encrypted data transfer and authentication. A more secure alternative to FTP.
The optimal protocol choice depends on the specific requirements of your application, weighing factors like security, performance, and ease of implementation.
Network Optimization Strategies
Several techniques improve network performance and, consequently, data transfer speed and scalability:
- Load Balancing: Distributing network traffic across multiple servers to prevent overload and ensure consistent performance.
- Caching: Storing frequently accessed data closer to the end-users to reduce latency and improve response times.
- Content Delivery Networks (CDNs): Geographically distributed networks of servers that cache and deliver content to users based on their location, minimizing latency and improving performance.
Data Streaming and Real-time Processing
For real-time applications, data streaming offers significant advantages over traditional batch processing methods.
Introduction to Data Streaming
Data streaming involves processing data as it arrives, rather than in batches. This allows for immediate analysis and response, enabling real-time insights and applications.
- Batch Processing: Processes data in large chunks, often involving significant delays.
- Streaming: Processes data continuously, allowing for real-time analysis and response.
Use cases for data streaming include real-time analytics dashboards, IoT data processing, and fraud detection systems.
Implementing Data Streaming Architectures
Several technologies facilitate data streaming architectures:
- Apache Kafka: A distributed streaming platform offering high throughput and fault tolerance.
- Apache Flink: A powerful stream processing framework for real-time applications.
- Spark Streaming: A component of Apache Spark for processing streaming data.
Building a robust data streaming system requires careful consideration of factors like scalability, fault tolerance, and data consistency. Each technology mentioned provides extensive documentation and resources to guide development.
Conclusion: Unlocking Performance and Scalability through Optimized Data Transfer
Optimizing transferred data involves a multifaceted approach encompassing compression techniques, deduplication strategies, optimized protocols, and efficient network architectures. By implementing the strategies outlined in this article, you can significantly improve application performance, scalability, and reduce operational costs associated with slow data transfer. This leads to faster response times, increased efficiency, and a better user experience. Start exploring the technologies mentioned—gzip, zstd, deduplication tools, HTTP/2, and data streaming platforms—to unlock the full potential of your data transfer processes and achieve greater application performance and scalability. Don't let slow data transfer hinder your success; begin optimizing transferred data today!
Featured Posts
-
 Understanding Xrp Ripple Could It Be Your Ticket To Financial Freedom
May 08, 2025
Understanding Xrp Ripple Could It Be Your Ticket To Financial Freedom
May 08, 2025 -
 Review Krypto The Last Dog Of Krypton Is It Worth Watching
May 08, 2025
Review Krypto The Last Dog Of Krypton Is It Worth Watching
May 08, 2025 -
 Batalla Campal Entre Flamengo Y Botafogo La Violencia Se Extiende A Los Vestuarios
May 08, 2025
Batalla Campal Entre Flamengo Y Botafogo La Violencia Se Extiende A Los Vestuarios
May 08, 2025 -
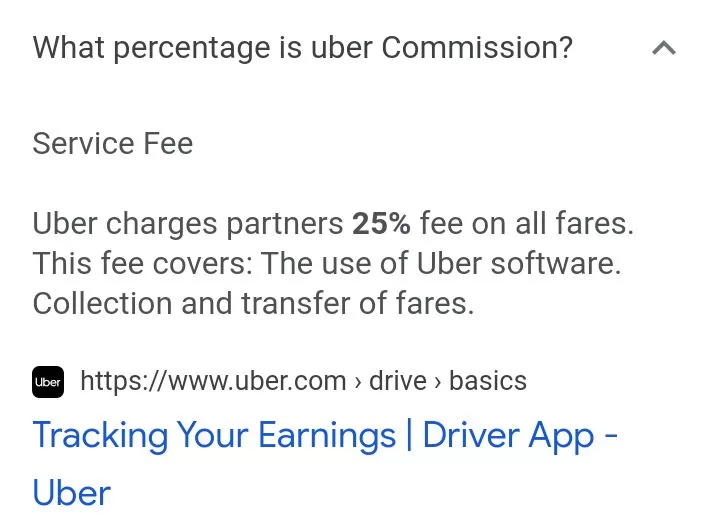 Increased Earnings For Uber Drivers And Couriers In Kenya Plus Cashback For Customers
May 08, 2025
Increased Earnings For Uber Drivers And Couriers In Kenya Plus Cashback For Customers
May 08, 2025 -
 The Colin Cowherd Jayson Tatum Debate A Persistent Point Of Contention
May 08, 2025
The Colin Cowherd Jayson Tatum Debate A Persistent Point Of Contention
May 08, 2025

